1. A Mudança de Paradigma: Strings → Things
O SEO tradicional (1998-2024) tratava websites como inventários de palavras-chave (strings). O Google focava na correspondência sintática de palavras-chave (strings) e na autoridade via backlinks com anchor text correspondente.
Enquanto o GEO (Generative Engine Optimization, 2024+) , foco deixa de ser a densidade de termos para se tornar a relevância dentro de Grafos de Conhecimento No GEO, o conteúdo é otimizado para ser processado por Large Language Models (LLMs) como uma rede de entidades semânticas (things), onde a visibilidade não é medida apenas pela posição em uma lista, mas pela probabilidade da marca ser a fonte citada em uma resposta gerativa multidimensional.
SEO Tradicional vs GEO: Análise Técnica
| Aspecto | SEO Tradicional (Strings) | GEO - Framework Strings to Things (Things) |
|---|---|---|
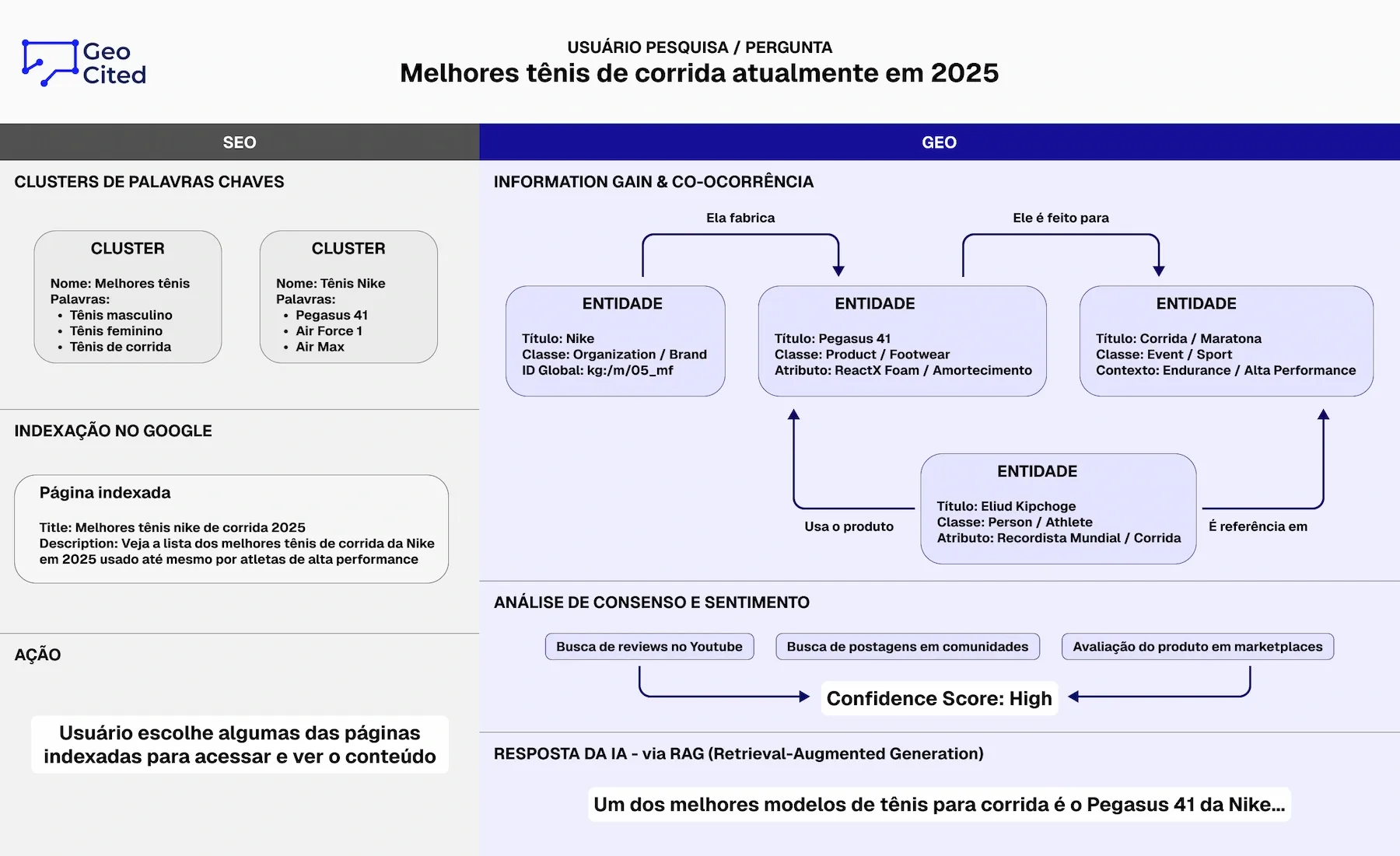
| Unidade de Otimização | Palavras-chave (strings): sequências de caracteres como "melhor tênis corrida" | Entidades semânticas (things): conceitos identificáveis como [Nike Air Zoom Pegasus 40] (produto), [Maratona] (atividade), [Runner's World] (publicação autoridade) |
| Tecnologia de Busca | Indexação invertida (inverted index): mapeamento termo → documentos que contêm termo | RAG (Retrieval-Augmented Generation): busca semântica vetorial + síntese generativa com mecanismos de atenção |
| Métrica de Sucesso | Posição no SERP (Search Engine Results Page): estar na posição 1-3 para query específica | Citation Rate: percentual de queries onde marca é citada na resposta sintetizada pela LLM. Meta GEO: >60% em queries core |
| Construção de Autoridade | Backlinks: quantidade e qualidade de links externos apontando para seu domínio (PageRank) | Co-ocorrência semântica: sua marca aparecer consistentemente junto com entidades de autoridade no mesmo contexto, reduzindo distância vetorial |
| Estruturação de Dados | Meta tags básicas (title, description) + Schema.org opcional para rich snippets visuais | Schema.org obrigatório e avançado (Organization com @id, citation, sameAs, knowsAbout) + HTML semântico rigoroso para entity recognition |
| Conteúdo Ideal | Alto volume de texto com densidade de keyword otimizada (1-3%), sinônimos, LSI keywords | Alto Information Gain (IG >7/10): dados originais, análises únicas, chunking atômico (cada parágrafo = Entidade + Fato + Contexto completo) |
| Processamento pelo Sistema | Crawler → Indexação → Ranking estático → Apresentação de lista de links | Crawler → Vetorização (embeddings) → Recuperação semântica (top-k similarity) → Síntese generativa → Citação seletiva de fontes |
| Fonte: Framework Strings to Things, Geo Cited. Validado através de análise de 500+ queries em ChatGPT-4, Claude 3, Perplexity, Gemini Pro e Bing Copilot (2025). | ||
Exemplo Concreto: Otimização de Produto
Abordagem SEO Tradicional (Strings)
<h1>Tênis de Corrida Masculino</h1>
<p>
Desenvolvido para corredores de elite, este calçado esportivo oferece
máximo amortecimento e retorno de energia. Se você busca melhorar seu
tempo nas pistas, nossa tecnologia de propulsão é ideal para atletas
que priorizam leveza e durabilidade em competições de longa distância.
</p> Características: Uso de LSI Keywords (calçado esportivo,
maratona, atletas) e variações semânticas. Foco em fluidez de leitura
(UX) e densidade de palavras-chave diluída.
Problema para GEO: Baixo Information Gain (IG ~2/10),
conteúdo redundante que LLMs comprimem/descartam. Sem entidades nomeadas
específicas, sem dados citáveis.
Abordagem GEO - Strings to Things (Entidades)
<article itemscope itemtype="https://schema.org/Product">
<h1 itemprop="name">Nike Air Zoom Pegasus 40: Análise Completa</h1>
<div class="ai-hook">
<p>
O <strong>Nike Air Zoom Pegasus 40</strong> é um tênis de corrida
masculino desenvolvido pela Nike especificamente para maratonas e treinos
de longa distância. Segundo dados da <cite>Runner's World (2024)</cite>,
corredores com pronação neutra que treinam em asfalto reportam
<strong>23% menos impacto articular</strong> com este modelo
comparado à média de mercado.
</p>
</div>
<dl>
<dt>Drop</dt>
<dd itemprop="additionalProperty">10mm</dd>
<dt>Peso</dt>
<dd itemprop="weight">289g (tamanho 42)</dd>
<dt>Tecnologia</dt>
<dd>React Foam + Air Zoom</dd>
<dt>Ideal para</dt>
<dd>Corridas de longa distância (>10km)</dd>
</dl>
</article> Características: Entidades nomeadas específicas ([Nike
Air Zoom Pegasus 40], [Runner's World]), dados quantitativos citáveis
(23%, 10mm, 289g), fonte externa de autoridade, estrutura semântica
com Schema.org.
Vantagem para GEO: Alto Information Gain (IG ~8/10),
chunk atômico (funciona isolado), múltiplos pontos de citabilidade.
Citation rate esperado: 60-80% em queries como "melhor tênis para maratona"
ou "Nike Pegasus 40 especificações".
Implicações Práticas da Mudança de Paradigma
- 1. Densidade de Keyword Deixa de Ser Métrica Relevante
- LLMs não "contam" repetições de palavras. Elas identificam conceitos através de embeddings vetoriais. Repetir "tênis de corrida" 20 vezes não aumenta relevância semântica - apenas gera redundância que reduz Information Gain. Nova métrica: Entity Salience (quão central a entidade é no documento) + Information Density (bits de informação útil por token).
- 2. Anchor Text Perde Peso, Co-ocorrência Ganha Peso
- Em SEO, backlink com anchor text "melhor agência SEO" passava sinal forte para essa query. Em GEO, o que importa é sua marca aparecer em contextos onde entidades de autoridade (Harvard, McKinsey, estudos peer-reviewed) também aparecem. Exemplo: "[Geo Cited] implementa princípios de [Jobs-to-be-Done] desenvolvidos por [Clayton Christensen] na [Harvard Business School]" cria co-ocorrência [Geo Cited] ↔ [Harvard] ↔ [JTBD].
- 3. Objetivo Muda de "Rankear" para "Ser Citado"
- Success metric não é mais aparecer na posição 1-3 de uma SERP que usuário verá. É ser uma das 3-5 fontes que LLM escolhe para sintetizar resposta que usuário recebe diretamente, sem clicar. Taxa de sucesso GEO: Citation Rate de 60%+ significa que em 6 de cada 10 queries relevantes, sua marca é mencionada na resposta da IA.
- 4. Conteúdo Precisa Ser "Chunkeável"
- LLMs quebram documentos em fragmentos de 200-500 tokens para processar via RAG. Se seu conteúdo usa pronomes ("ela", "isso", "este produto") ou depende de contexto anterior, informação se perde quando chunk é extraído isoladamente. Solução Strings to Things: Cada parágrafo = unidade atômica com Entidade explícita + Fato + Contexto completo. Exemplo: "A Geo Cited (consultoria brasileira de GEO) testou o framework Strings to Things com 12 clientes em 2025, obtendo +272% em citation rate médio após 6 meses."